ECCV 2020에서 발표된 DETR(End-to-End Object Detection with Transformers) 논문 리뷰입니다.
DETR은 기존 NLP 테스크에서 주로 사용되던 Transformer 구조를 Object Detection에 적용한 모델로, end-to-end 방식으로 객체 탐지를 수행하면서도 높은 성능을 보이는 것이 특징입니다. 또한 현재 Object Detection 분야의 SOTA 모델 중 상당수가 DETR을 기반으로 발전했기 때문에, 한 번쯤 읽어볼 가치가 있는 논문입니다.
이 리뷰에서는 NLP 테스크에서의 Transformer 구조와 Object Detection 테스크에서의 차이점, DETR 모델의 Loss 함수 분석, 학습 비용 및 방법에 대해 다룰 예정입니다.
문제 정의
기존 object detection 모델에서는 다수의 anchor 생성, NMS와 같은 후처리 과정이 무조건적으로 진행되고 있습니다.
이 논문에서 저자는 이와 같은 후 처리 과정을 사용할 필요없이, 이진 매칭을 통해 중복 예측을 방지하는 transformer 기반의 end to end 모델 DETR을 제시합니다.
Transformer for NLP task vs DETR Transformer
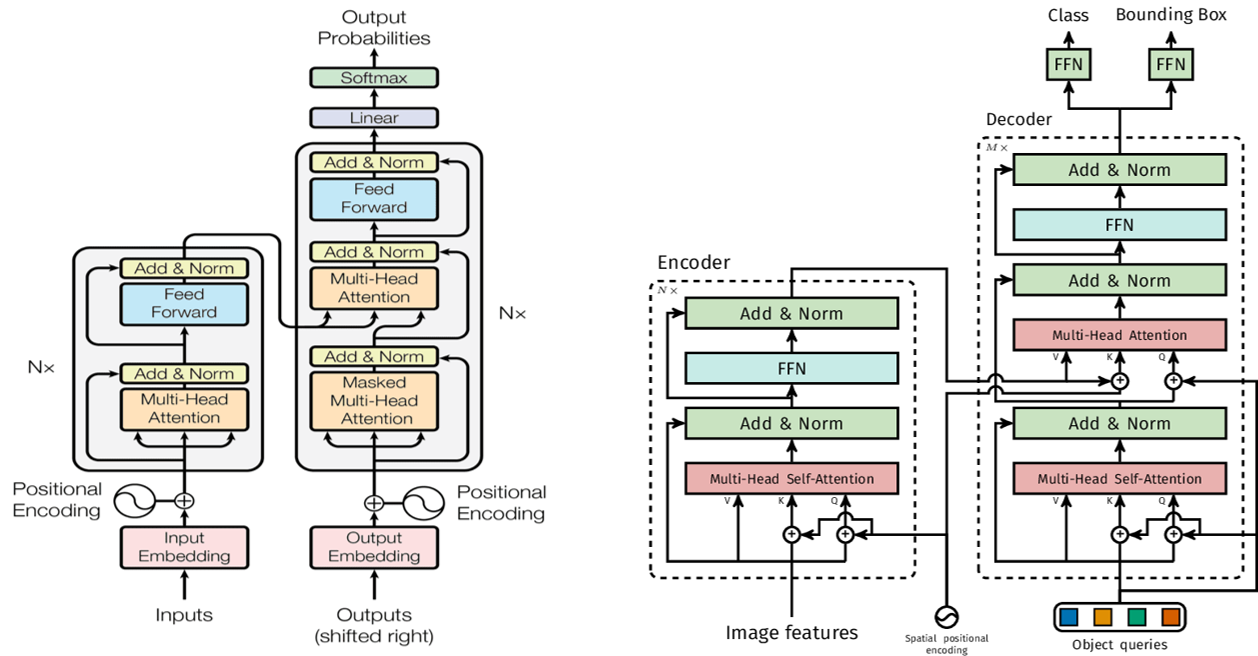
NLP 테스크에서 사용되는 트랜스포머 구조와 DETR(Detection Transformer)의 가장 큰 차이점은 Self-Attention과 Object Query의 유무입니다. 기존 NLP 트랜스포머에서는 포함되어 있지 않은 Self-Attention 방식과 Object Query 개념이 DETR 구조에서 중요한 요소로 자리 잡고 있습니다. 이 두 가지 개념에 대해 자세히 살펴보겠습니다.
Self Attention
Object Detection 태스크에서 Self-Attention은 속도 향상에 중요한 요소로 작용합니다. 일반적인 Attention을 사용하면 여러 레이어를 거치면서 각각 Query, Key, Value 값을 연산해야 하지만, Self-Attention은 한 레이어에서 한 번의 입출력만으로 Query, Key, Value를 생성할 수 있습니다. 이러한 특성 덕분에 DETR에서 Self-Attention이 적용되었다고 볼 수 있습니다.
또한, DETR의 Decoder 구조를 살펴보면 마지막에는 Self-Attention 대신 일반 Attention Layer가 사용됩니다. 이는 이미 입력 값인 Query, Key, Value가 생성된 상태에서 추가적인 변형 없이 그대로 사용하는 것이 더 좋은 성능을 내기 때문입니다. 결과적으로 DETR의 구조는 이러한 점들을 고려하여 효율적으로 최적화되었다고 볼 수 있습니다.
Object Query
Object Query는 Object Query Features, Object Query Positional Embedding (위치 정보 제공)로 구성되어 있으며, 이 두 가지는 모두 학습이 가능한 요소입니다.
- Object Query Features (주체, 주요 역할)
- 디코더의 초기 입력 값으로 사용되며, 초기 값은 0으로 설정됩니다.
- 고정된 개수(N개)만큼 생성되며, 학습 전에 초기화됩니다.
- 이 개수는 하이퍼파라미터로 설정할 수 있으며, 논문에서는 100개로 설정되었습니다.
- 객체의 bounding box (bbox) 정보를 포함하고 있습니다.
- 디코더의 각 레이어를 통과하면서 계속 업데이트됩니다.
- 이때, spatial positional encoding과 positional embedding의 위치 정보가 업데이트를 돕습니다.
- 즉, 매 디코더 레이어마다 새로운 정보가 반영되면서 점점 더 정확한 객체 정보를 갖게 됩니다.
- Object Query Positional Embedding (위치 정보 제공)
- 학습 전에 초기화되며, 객체 쿼리의 위치 정보를 인코딩하는 역할을 합니다.
- 모델이 각 쿼리가 어떤 객체를 예측하는지 학습할 수 있도록 돕습니다.
- 순전파(Forward Pass)에서는 업데이트되지 않고,
- 역전파(Backpropagation) 이후에만 업데이트됩니다.
요약:
- Object Query Features는 객체를 탐색하는 주요 정보이며, 디코더를 거치면서 점점 업데이트됩니다.
- Object Query Positional Embedding은 각 쿼리의 위치 정보를 제공하는 역할을 하며, 역전파 이후에만 업데이트됩니다.
Set Prediction Loss
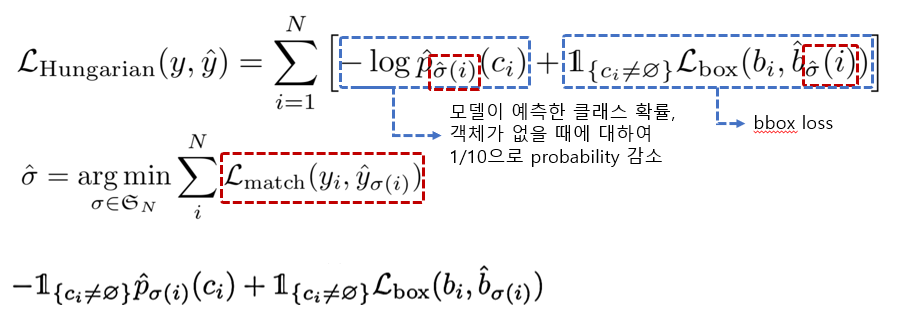
𝑁 == object query의 지정된 예측 개수(논문에서는 100개로 set)
𝑐𝑖 == ground truth class
𝑏𝑖 == ground truth bbox
빨간색으로 표시된 부분은 매칭 함수이며, 최적의 매칭 값을 보이는 bbox의 인덱스 값을 산출합니다.
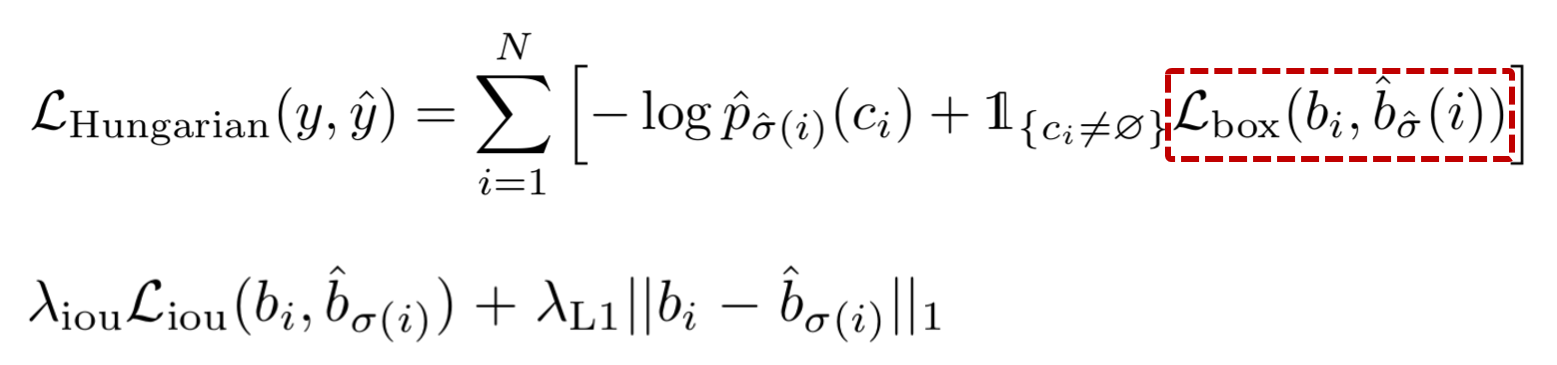
DETR 모델은 box loss 계산을 위하여 GIoU와 L1 loss의 조합을 사용합니다.
GIoU + L1 loss:
가장 일반적으로 사용되는 L1 loss는, 작은 박스와 큰박스의 상대오차가 비슷하더라도 서로 다른 크기의 값을 가지게 됩니다. 이러한 문제를 완화하기 위해 DETR 모델은 L1 loss와 GIoU(generalized IoU loss)의 조합을 사용합니다.
GIoU란,
- 기존 IoU - (C box 중 A와 B 모두와 겹치지 않는 영역의 비율)
- ground truth bbox에 대해서 overlap하기 위해 영역을 넓혔다가, 다시 IoU 값을 높이기 위해 bbox의 영역을 축소시키는 과정을 통해 값이 산출됩니다.
- 겹치지 않는 박스에 대한 기울기 소실(gradient vanishing) 문제는 개선했지만, 수렴 속도가 느리고 부정확하게 (horizontal과 vertical 정보 표현이 X) 박스를 예측한다는 문제점이 존재합니다.
사용된 데이터 셋
- coco 2017 object detection dataset
학습 및 추론 비용
논문에서 언급된 바로는, 베이스 모델 학습시 300 epoch로 16개의 V100 GPU로 3일간 진행이 되었다고 합니다. (batch size 64, gpu당 4장씩 학습)
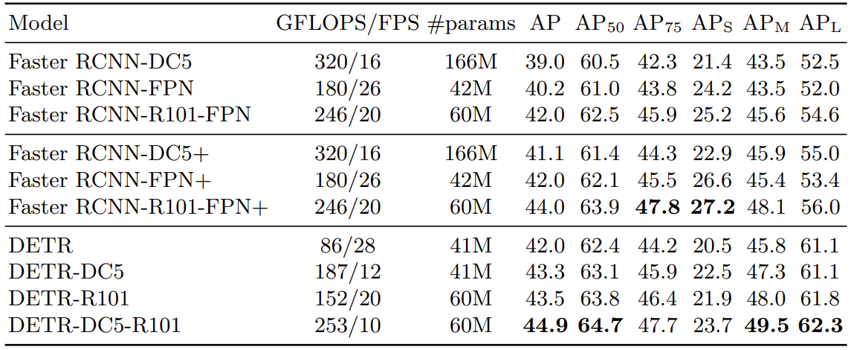
아래는 논문에서 발췌한 모델별 추론 성능표입니다. 논문에서 비교가 된 Faster RCNN의 경우도 함께 적혀있으니 참고하시면 좋을 것 같습니다.